
EdgeAnt: pushing AntidoteDB to the Edge
Pre-implementation: System specification and design
1. Introduction :
Cloud-scale services improve availability and latency by geo-replicating data in several data centers (DC) across the world. Nevertheless, the closest DC is often still too far away for an optimal user experience. To remain available at all times, client-side applications need to cache data at client machines, caching data at client machines can improve availability and latency for many applications, and also allow for temporary disconnection. This approach is used in many recent cloud services, like Google Drive RT API or Mobius [3, 5, 9, 16], where developers implement caching and buffering at application level, but it doesn’t ensure system-wide consistency guarantees.Although pushing geo-replication to the Edge client machine seems natural, it raises two main challenges. The first one is to provide programming guarantees for applications running on client machines, at a reasonable cost at scale and under churn. Recent DC centralized storage systems in literature [8, 6, 14, 15, 19] provide transactions and combine support for causal consistency with mergeable objects. Extending these guarantees to the client is problematic for a number of reasons: standard approaches to support causality in client nodes require vector clocks entries proportional to the number of replicas; seamless access to client and server replicas require careful maintenance of object versions; fast execution in the client requires asynchronous commit. We developed a framework, called EdgeAnt, that efficiently address these issues despite failure, by extending a set of techniques designed in the previous SwiftCloud work [21].
Client-side execution is not always beneficial. For instance, computation that access a lot of data, such as search or recommendations, or running strongly consistent transactions, is better done in the DC. EdgeAnt provides a module for server-side execution, without breaking the guarantees of client-side in-cache execution.
The second challenge is to maintain these guarantees when the client to DC connection breaks. While many web applications are stateless, fetching data from servers whenever necessary, a number of applications cache data on the client for providing disconnected operations. For example Google Docs, Maps and Facebook support offline access [11]. When failure or disconnection happens, the client can reconnect to another DC, in this case the new DC may be in a state where he misses the causal dependencies of the client. Previous cloud storage systems either retract consistency guarantees in similar cases [13, 15], or avoid the issue by waiting for writes to finish at a quorum of servers [19], which incurs high latency and may affect availability.
In this work we provide a client-assisted failover protocol that preserves causality cheaply, as in SwiftCloud design [21]. The insight is that, in addition to its own updates, a client may observe a causally-consistent view of stable (i.e., stored at multiple servers) updates from other users. This approach ensures that client’s updates are not delayed, and that the client’s cached state matches the new DC, since it can replay its own updates and the other are known to the DC.
The third challenge, is to avoid unnecessary latency when relying on centralized servers for mediating user interaction among each other. Today, many cloud applications are designed around collaborative interactions between users [20, 17, 18], from distributed file systems, to multilayer games.
This work extends the previous guarantees to collaborative groups of clients, adding peer-to-peer communications on shared services at the edge, and making the system less dependent on the centralized server, and network.
In this blog post, I will present the status of my design thinking, and how I plan to address all those challenges.
2. System Overview
Let me now describe a system design that addresses the above challenges, first the DC side component, and next the approach used for the client cache and how we improved it to fit implementation. Our design builds a cloud-based support for partial client replicas.
2.1. Backend Storage
Cloud applications are generally built on top of a distributed database running in a Data Center (DC). Developers of cloud applications face a difficult decision of which kind of storage to use, defined by the CAP theorem [12], according to which distributed database design must sacrifice either string consistency or availability, since network failures are unavoidable. Traditional databases are ”CP”, they provide strong consistency and a simple SQL interface, but are slow and unavailable under partition. NoSQL databases are ”AP”, fast and available under partition, but too hard to program against as it expose application developers to inconsistency low-level anomalies.
Recent literature focused on adding strong semantics to AP databases design [15, 14, 10]. Our system goes in the same direction, we want to provide the highest level of consistency guarantees that remains compatible with availability.
Causal+ consistency (CC+) [15] is a good compromise between availability and consistency, it guarantees that individual operations will be seen in causal order, with ease to use for programmers. It is considered being the strongest model compatible with availability [4].
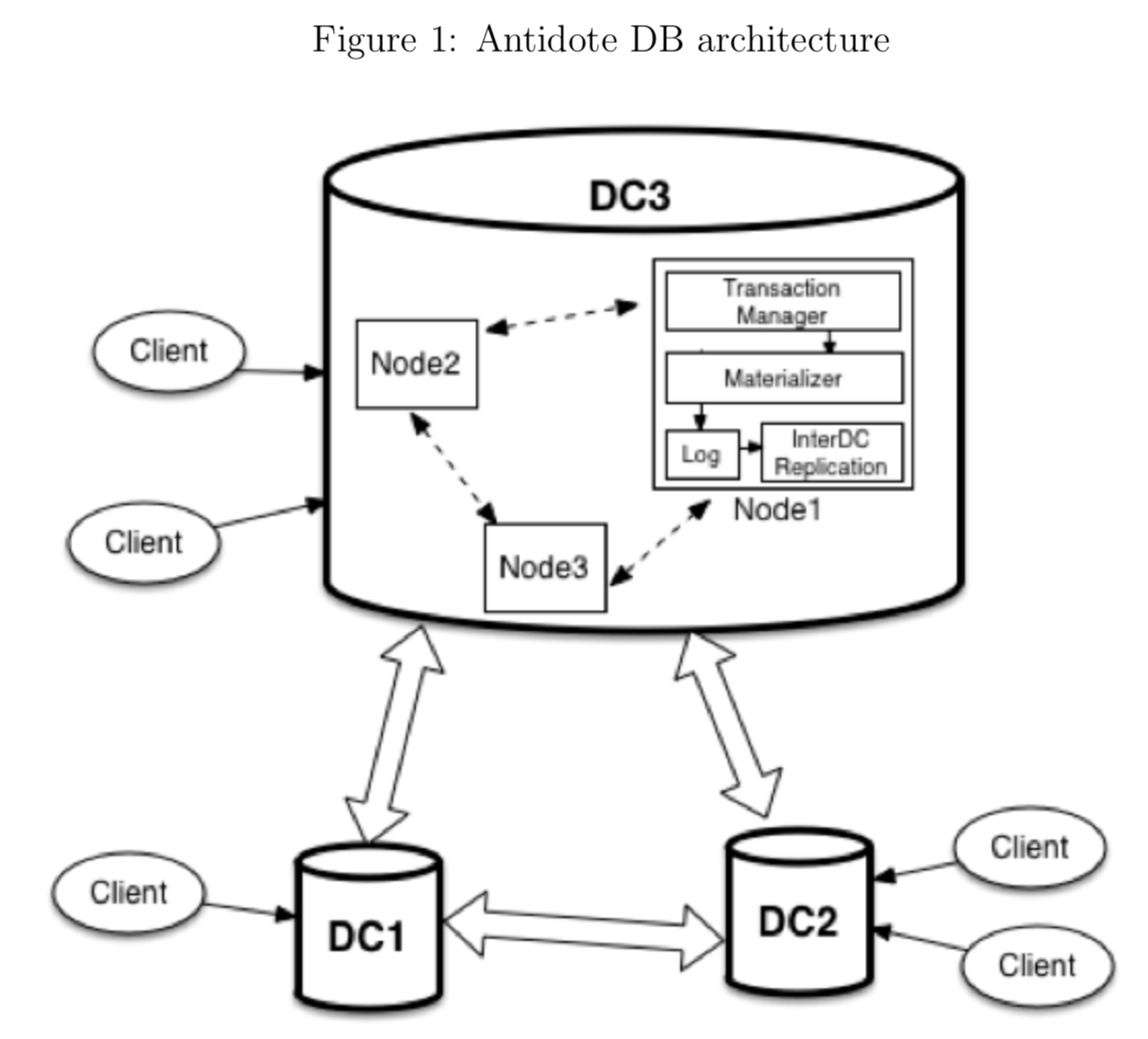
Antidote is a highly-available geo-replicated database with strong guarantees. Antidote uses Cure [2], a highly scalable protocol, to replicate the updates from one cluster to other. The updates are replicated asynchronously to provide high availability under network partitions. Cure provides causal consistency [1] which is the strongest consistency model compatible with high availability. Causal consistency guarantees that related events are made visible according to their order of occurrence, while the unrelated events (events that occurred concurrently) can be in different order in different replicas. Cure also allows applications to pack multiple reads and writes to multiple objects in a transaction.
Antidote is a highly available geo-replicated key-value database. Antidote provides features that help programmers to write correct applications while having the same performance and horizontal scalability as AP/NoSQL databases.
A data center of Antidote may have more than one server to support a large database that cannot be stored in a single machine. A data center stores a full replica of the database. Each server manages multiple virtual partitions that stores a non-overlapping set of objects determined using consistent hashing. An Antidote deployment consists of more than one data center located across the globe. Each data center may have a different number of servers but uses the same consistent hashing mechanism to determine the partitions.
2.2. Client side design: The SwiftCloud approach
Introduced by Zawirski et al. [21], the goal of the SwiftCloud approach is to extend geo-replication all the way to the client machine, pushing consistency, convergence and availability guarantees to the client cache, at a reasonable cost.
Client-side cache Each client is connected to an Antidote data center, and is interested, at any point of time, in a subset of the objects in the database, called its interest set. The client cache only needs to store the objects of its interest set. Initially, the client cache is a projection of data center’s state, that is causally consistent. Any update, either generated by the client or delivered by the data center, maintains causal consistency. This approach ensures that a client replica commits updates without waiting, and transfers them to its data center asynchronously.
Invariants The system guarantees the invariant that every node (DC or cache) maintains a causally-consistent set of object versions. Data is fully-replicated in a DC, and to be able to serve any version requested by the client-side cache, multiple versions of an object will be stored in the DC.
On each DC, data is sharded to multiple server non-overlapping partitions, a vector clock VP is maintained by each partition P. Any entry VPi [j] counts the number of transactions committed by Pj that Pi has processed. Each DC has a vector clock VDC that maintains globally stable consistent snapshot commit time, that is the snapshot time available on all its partitions. On the client cache side, a vector clock VC stores the most recent version of cached objects, one entry for each DC, and an additional entry for local transactions.
Transactions protocol Each transaction in the client cache generates an identifier composed of a monotonically increasing timestamp and a unique cache identifier. A vector clock is also allocated to summarize the causal dependencies of the transaction. API functions read and multi_read returns a version of the requested object (or multiple objects for multi_read) that guarantees causal consistency. If the requested object is missing in the cache, it is fetched from the DC, and if its version is not valid, the read fails. Update operations effects are logged when an operation is executed on a previously read object, then cache’s entry in VC is updated with transaction’s timestamp. The updates are made immediately visible to the client issuing them.
Each committed update at the client log is transmitted to its current DC. The client waits for an acknowledgment that contains the timestamp assigned by the DC to its update. In case of transfer failure (communication timeout or DC missing some causal dependencies) the client is switched to another DC. In the other way, client can subscribe to objects updates in the DC. In this case, the DC will maintain a FIFO best-effort channel to the client, sending a causal stream of update notifications. Those notifications contain the log updates to the objects of the client’s interest set, which are then applied to its local state.
K-Stability When a DC fails, client is switched to another one. The state of the new DC may miss some client’s causal dependencies. SwiftCloud’s approach is to make the client cache co-responsible for the recovery of missing session causal dependencies at the new DC. We define a transaction to be K-stable at a DC, if it has been applied in at least K DCs, where K is configurable. More precisely, a client can observe the union of: (i) its own updates, and (ii) the K-stable updates made by other clients. The client can move to an other DC, as long as this new DC ensures that the client continues to observe a monotonically-growing set of K-stable updates.
2.2. Implementation: EdgeAnt
As we described in the previous section, the Swiftcloud approach [21] extends the data center causal consistency guarantees to the client local storage. The Swiftcloud system provides guarantees and techniques such as Read-Your-Writes, partial replication, K-stability, monotonic operations and small metadata design for tracking causality.
Based on the previous work, we implemented EdgeAnt, a client cache storage wish ensures the same consistency, convergence and fault-tolerance properties of Swiftcloud, using Antidote DB as a back-end storage, a rich API model and data/computation placement flexibility.
Design and requirements overview We consider a system model composed of a small set of powerful and geo-replicated Data Centers running Antidote DB (as described in section 2.1), and a large set of limited resources clients.
Each DC hosts a full replica of data, and DCs are connected in a peer-to-peer manner. Antidote uses Cure protocol replication and its storage is operation-based which requires some protocol adaptation at clients partial-replica. DC can fail and recover from its persistent storage.
Clients stores a small and partial replica of the data, called there interest set, thus, an operation achieves high availability when the requested object is cached, but needs a remote communication when the object is missing in the local cache. Each EdgeAnt client is connected to a single DC, clients do not communicate directly. A client may disconnect, make offline local updates, than reconnect to its original DC or another one.
The client cache is mostly a small and size-bounded memory space, thus, it cannot contain a total replica of the data store. A common approach to solve this problem is to use partial replication [7], so each client cache contains only part of the database and its metadata.
As in Swiftcloud, EdgeAnt decouples metadata design separating tracking causality, which is done using vector clocks in the DC side, and unique identification, based on scalar timestamps assigned in the client side. Thanks to this design, and K-stability, metadata remains small and size-bounded.
Client API EdgeAnt being a simple extension to the edge, applications can interact with EdgeAnt the same way they could interact with Antidote DB, using its Erlang and Java Protocol Buffer interface. Application can also use interactive transactions where they first starts the transaction, then read/update one/multiple objects, and finally commit the transaction.
Transactions protocol When the EdgeAnt client first connect to the DC, it’s assigned a global unique identifier composed of a scalar id and original DC id, this identifier will be attached to all transactions to ensure the ”Only applied once” property, especially in the case when the client moves and applies its updates to another DC, each operation will be then assigned a vector clock timestamp with respect to Cure protocol. EdgeAnt client first connection also caches its initial state with the object from its first interest set, as explained in section 2. The interest set of object keys is dynamically updated by the client, and is also stored in the DC side which will send back K-stable updates for its object.
Local updates are ordered using a scalar timestamp, the Commit Protocol (from client to DC) sends clients local commits to its connected DC, in background. In the DC side, received updates are applied with respect to clients timestamps order, causal dependencies (they can be client internal or external, the DC can report missing dependencies to the clients) and the ”Not applied twice” property. Then the geo-replication is done with respect to K-stability and Cure’s stabilization protocol. Finally, the DC answers back to the client with the assigned vector clock, if this answer is not received, the client raises a DC failure and switch to another DC.
Each connect client has an EdgeAnt Session in the DC side, like AntidoteDB, EdgeAnt allows atomic transactions across partitions, the EdgeAnt Session coordinates reads and updates to multiple objects stored in different partitions, this process maintains not only the interest set but also the last known snapshot vector used by the client.
Periodically, the DC will send over this session channel, a causal stream of updates. This notification update consists of a log of updates to the objects of the interest set, that are between the last know snapshot vector and the new one. This log can be empty, as we want also to notify the client when the snapshot vector changes due to external dependencies, and avoid causal gaps.
3. Ongoing and future work
Moving computation Client computation resources can be poor and limited, although being resource-friendly and metadata lightweight, in EdgeAnt, some heavy operation can be done faster using the DC power. We are currently exploring a hybrid model where we can move computation from the client to the server in the heavy jobs case. This raises some interesting challenges like preserving the causal state of the client, handling updates and scheduling operations.
Clients groups Today, many cloud applications are designed around collaborative interactions between users, from distributed file systems, to multi-player games. For many web services, relying on centralized servers for mediating user interactions among each other leads to unnecessarily latency: as the servers have to manage all the transactions synchronization, the latency increases with clients requests number, with servers availability and in most cases the closest server is still far away compared to the closest client.
The goal of this work is to extend EdgeAnt guarantees to collaborative groups of clients, adding peer-to-peer communications on collaborative services at the edge, making the system less dependent on the centralized server.
To reach this goal, we are extending the EdgeAnt system with new features:
- Shared caches: each client maintains a local cache with shared objects needed for the shared application. We adopt a strong consistency model where updates to the local cache are propagated synchronously with other users from the same groups, as the strong consistency model is easier to implement for a shared journal of operations. Another option would be to rely on Conflict-free Replicated Data Types (CRDTs) to make replicas converge to the same state despite concurrent updates.
- Network Independence: in many video games and documents collaboration use-cases, groups of clients can be interconnected in a separated network, or have a poor internet bandwidth. In our design, we provide the ability to collaborate on the shared cache even when clients are disconnected from the server.
- Dynamic groups membership: in any point of time, a client can move from one group to another. This raises some interesting research problems as the new host group can make concurrent updates to the moving clients previous state, so we are developing a mechanism to merge divergent groups updates without the need to synchronize with the server.
4. Conclusion
We presented the origin and design of EdgeAnt, a system that brings geo-replication guarantees to the Edge. EdgeAnt allows applications to run transactions in the client machine, for common operations that access a limited set of objects, with immediate, consistent and offline response, or in the DC, for transactions that require accessing a large number of objects. EdgeAnt also proposes a client-assisted fail-over mechanism that trades latency by a small increase in staleness.
Several aspects remain open for improvements. Better caching heuristics, and support for transaction migration, would help to avoid the high latency caused by successive cache misses. Placing clients at different levels of hierarchy, in particular in Content Delivery Network points of presence, might improve perceived latency even more. Adding peer-to-peer communications on shared services, making the system less dependent on the centralized server.
5. Related Work
Data placement and replication factors are a critical aspect when building highly-available systems extending to edge devices. In contrast to caching systems, partial replication provides means for asynchronous updates on the edge device.
Achieving low latency for web-based applications is an on-going challenge for many web applications [22, 23, 24]. For example, on amazon.com, a delay of 100ms costs in average 1% of sales [23]. In order to deliver fast response and offline support, a number of web applications started caching data on the edge. Facebook designed News Feed [25] to support offline access; Google Docs and Google Maps can also be used offline via Chrome browser extension [26].
Many prior work efforts have studied data management in settings where clients are intermittently connected to servers or to peers. Bayou [27] pushed data replicas to the edge in the context of mobile environments (Terry [28] presents an excellent synthesis on the topic), then Cimbiosys [29] extended the decentralized synchronization model to Internet Services, in addition to Rover [30] and Coda [31], those systems supports disconnected operations but rely on a weak consistency model.
Recently, Parse [32] and Cloud Types [33] are programming models for shared cloud data, they allow local data copies to be stored on the edge client and later be synced with the cloud, but provides only an eventual consistency model.
In prior work, we have explored protocols for partial replication on clients extending a geo-replicated data-store. Swiftcloud [21] allows programmers to dynamically specify a set of objects that is replicated on clients residing in points-of-presence. It allows an offline-first approach with low latency by building on CRDTs and transactional causal consistency. Swiftcloud targets the same high availability techniques as PRACTI [34] and Depot [24], but the later two uses a fat metadata approach (version vectors sized as the number of clients) and they support only LWW registers (but their rich metadata design could support CRDTs too). Swiftcloud further guarantees that updates are neither duplicated nor lost when failing over to other DCs in case of (temporary or final) disconnection with some DC. Depot [35] support Byzantine faults tolerance, a more difficult class of faults than Swiftcloud. However it is not designed to scale to large numbers of clients, to co-locate data with the user without placing a server in the edge machine, nor does it support transactions. Recently, Simba [36] provides the ability for the edge application to select the level of desired observable consistency (eventual, causal or serializability).
In our current work on EdgeAnt, we retarget our work on Swiftcloud to AntidoteDB with extensions to direct communication between edge clients.
Bibliography :
[1] M. Ahamad, M. Raynal, and G. Thia-Kime. An adaptive protocol for implementing causally consistent distributed services. In Distributed Computing Systems, 1998. Proceedings. 18th International Conference on, pages 86–93. IEEE, 1998.
[2] D. D. Akkoorath, A. Z. Tomsic, M. Bravo, Z. Li, T. Crain, A. Bieniusa, N. Pregui ̧ca, and M. Shapiro. Cure: Strong semantics meets high avail- ability and low latency. In Distributed Computing Systems (ICDCS), 2016 IEEE 36th International Conference on, pages 405–414. IEEE, 2016.
[3] S. Almeida, J. Leita ̃o, and L. Rodrigues. Chainreaction: a causal+ consistent datastore based on chain replication. In Proceedings of the 8th
ACM European Conference on Computer Systems, pages 85–98. ACM, 2013.
[4] H. Attiya, F. Ellen, and A. Morrison. Limitations of highly-available eventually-consistent data stores. IEEE Transactions on Parallel and Distributed Systems, 28(1):141–155, 2017.
[5] P. Bailis, A. Ghodsi, J. M. Hellerstein, and I. Stoica. Bolt-on causal consistency. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, pages 761–772. ACM, 2013.
[6] J. Baker, C. Bond, J. C. Corbett, J. Furman, A. Khorlin, J. Larson, J.-M. Leon, Y. Li, A. Lloyd, and V. Yushprakh. Megastore: Provid- ing scalable, highly available storage for interactive services. In CIDR, volume 11, pages 223–234, 2011.
[7] N. M. Belaramani, M. Dahlin, L. Gao, A. Nayate, A. Venkataramani, P. Yalagandula, and J. Zheng. Practi replication. In NSDI, volume 6, pages 5–5, 2006.
[8] J. C. Corbett, J. Dean, M. Epstein, A. Fikes, C. Frost, J. J. Furman, S. Ghemawat, A. Gubarev, C. Heiser, P. Hochschild, et al. Spanner: Googles globally distributed database. ACM Transactions on Computer Systems (TOCS), 31(3):8, 2013.
[9] J. Du, S. Elnikety, A. Roy, and W. Zwaenepoel. Orbe: Scalable causal consistency using dependency matrices and physical clocks. In Proceed- ings of the 4th annual Symposium on Cloud Computing, page 11. ACM, 2013.
[10] J. Du, C. Iorgulescu, A. Roy, and W. Zwaenepoel. Gentlerain: Cheap and scalable causal consistency with physical clocks. In Proceedings of the ACM Symposium on Cloud Computing, pages 1–13. ACM, 2014.
[11] Facebook. Continuig to build News Feed for all types of con-
nections, 2015. https://newsroom.fb.com/news/2015/12/ news-feed-fyi-continuing-to-build-news-feed-for-all-types-of-connections/.
[12] S. Gilbert and N. Lynch. Brewer’s conjecture and the feasibility of consistent, available, partition-tolerant web services. Acm Sigact News, 33(2):51–59, 2002.
[13] C. Li, D. Porto, A. Clement, J. Gehrke, N. M. Pregui ̧ca, and R. Ro- drigues. Making geo-replicated systems fast as possible, consistent when necessary. In OSDI, volume 12, pages 265–278, 2012.
[14] W. Lloyd, M. J. Freedman, M. Kaminsky, and D. G. Andersen. Don’t settle for eventual: scalable causal consistency for wide-area storage with cops. In Proceedings of the Twenty-Third ACM Symposium on Operating Systems Principles, pages 401–416. ACM, 2011.
[15] W. Lloyd, M. J. Freedman, M. Kaminsky, and D. G. Andersen. Stronger semantics for low-latency geo-replicated storage. In NSDI, volume 13, pages 313–328, 2013.
[16] P. Mahajan, L. Alvisi, M. Dahlin, et al. Consistency, availability, and convergence. University of Texas at Austin Tech Report, 11, 2011.
[17] D. Perkins, N. Agrawal, A. Aranya, C. Yu, Y. Go, H. V. Madhyastha, and C. Ungureanu. Simba: Tunable end-to-end data consistency for mobile apps. In Proceedings of the Tenth European Conference on Com- puter Systems, page 7. ACM, 2015.
[18] V. Ramasubramanian, T. L. Rodeheffer, D. B. Terry, M. Walraed- Sullivan, T. Wobber, C. C. Marshall, and A. Vahdat. Cimbiosys: A platform for content-based partial replication. In Proceedings of the 6th USENIX symposium on Networked systems design and implementation, pages 261–276, 2009.
[19] Y. Sovran, R. Power, M. K. Aguilera, and J. Li. Transactional storage for geo-replicated systems. In Proceedings of the Twenty-Third ACM Sym- posium on Operating Systems Principles, pages 385–400. ACM, 2011.
[20] A. van der Linde, P. Fouto, J. Leita ̃o, N. Pregui ̧ca, S. Castin ̃eira, and A. Bieniusa. Legion: Enriching internet services with peer-to-peer inter- actions. In Proceedings of the 26th International Conference on World Wide Web, pages 283–292. International World Wide Web Conferences Steering Committee, 2017.
[21] M. Zawirski, N. Pregui ̧ca, S. Duarte, A. Bieniusa, V. Balegas, and M. Shapiro. Write fast, read in the past: Causal consistency for client- side applications. In Proceedings of the 16th Annual Middleware Con- ference, pages 75–87. ACM, 2015.
[22] Akamai new study reveals the impact of travel site performance on consumers. http://www.akamai.com/html/about/press/releases/2010/press 061410.html. Published: June 14, 2010.
[23] Ron Kohavi and Roger Longbotham. Online experiments: Lessons learned. Com- puter, 40(9), 2007.
[24] Tom Leighton. Improving performance on the internet. Communications of the ACM, 52(2):44–51, 2009.
[25] Facebook: continuing to build news feed for all types of connections. https://code. fb.com/android/continuing-to-build-news-feed-for-all-types-of-connections/ l. Published: Dec 09, 2015.
[26] Google Docs: offline access. https://support.google.com/docs/answer/ 6388102?co=GENIE.Platform%3DDesktop.
[27] Douglas B Terry, Marvin M Theimer, Karin Petersen, Alan J Demers, Mike J Spre- itzer, and Carl H Hauser. Managing update conflicts in bayou, a weakly connected replicated storage system. In ACM SIGOPS Operating Systems Review, volume 29, pages 172–182. ACM, 1995.
[28] Douglas B Terry. Replicated data management for mobile computing. Synthesis Lectures on Mobile and Pervasive Computing, 3(1):1–94, 2008.
[29] Venugopalan Ramasubramanian, Thomas L Rodeheffer, Douglas B Terry, Meg Walraed-Sullivan, Ted Wobber, Catherine C Marshall, and Amin Vahdat. Cim- biosys: A platform for content-based partial replication. In Proceedings of the 6th USENIX symposium on Networked systems design and implementation, pages 261– 276, 2009.
[30] Anthony D Joseph, Alan F de Lespinasse, Joshua A Tauber, David K Gifford, and M Frans Kaashoek. Rover: A toolkit for mobile information access. In ACM SIGOPS Operating Systems Review, volume 29, pages 156–171. ACM, 1995.
[31] James J Kistler and Mahadev Satyanarayanan. Disconnected operation in the coda file system. ACM Transactions on Computer Systems (TOCS), 10(1):3–25, 1992.
[32] Parse Blog. Parse: website. https://parseplatform.org/.
[33] Sebastian Burckhardt, Manuel Fa ̈hndrich, Daan Leijen, and Benjamin P Wood. Cloud types for eventual consistency. In European Conference on Object-Oriented Programming, pages 283–307. Springer, 2012.
[34] Nalini Moti Belaramani, Michael Dahlin, Lei Gao, Amol Nayate, Arun Venkatara- mani, Praveen Yalagandula, and Jiandan Zheng. Practi replication. In NSDI, vol- ume 6, pages 5–5, 2006.
[35] Prince Mahajan, Srinath Setty, Sangmin Lee, Allen Clement, Lorenzo Alvisi, Mike Dahlin, and Michael Walfish. Depot: Cloud storage with minimal trust. ACM Transactions on Computer Systems (TOCS), 29(4):12, 2011.
[36] Dorian Perkins, Nitin Agrawal, Akshat Aranya, Curtis Yu, Younghwan Go, Har- sha V Madhyastha, and Cristian Ungureanu. Simba: Tunable end-to-end data con- sistency for mobile apps. In Proceedings of the Tenth European Conference on Computer Systems, page 7. ACM, 2015.